سامانهٔ Automatic Speech Recognition) ASR) یا همان تشخیص گفتار خودکار، فناوری ای است که به ماشین ها امکان می دهد واژه ها و جملات صوتی را به متن تبدیل کنند. مسیر تکامل این فناوری از دههٔ ۱۹۵۰ تا امروز، داستانی از نوآوری، چالش و تحول است. در ادامه به بررسی این مسیر، کاربردها، چالش ها و چشم اندازهای آینده می پردازیم.
آغاز داستان: دهه ۱۹۵۰ تا ۱۹۶۰
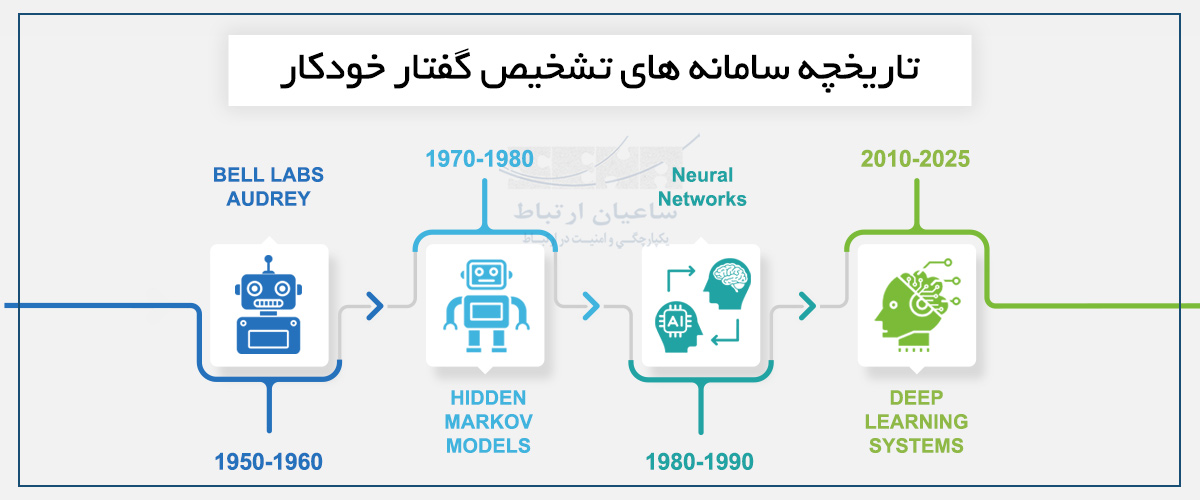
اولین سیستم شناخته شده تشخیص گفتار به سال ۱۹۵۲ باز می گردد، زمانی که Bell Labs سیستم Audrey را معرفی کرد؛ سیستمی که می توانست اعداد صفر تا نه را تشخیص دهد. اگرچه بسیار ابتدایی و کند بود، اما نشان داد امکان تبدیل گفتار به داده توسط ماشین وجود دارد.
در این دوره تمرکز بر تشخیص محدود بود، مثلاً واژه های بسیار محدود، یک گوینده واحد و محیط صوتی کنترل شده. فناوری های پسین بر همین پایه بنا شدند.
پیشرفت آماری و معرفی مدل های مارکوف: دهه ۱۹۷۰
در دههٔ ۱۹۷۰ تحولی بنیادی در ASR رخ داد. ورود مدل های پنهان مارکوف (HMM) امکان تحلیل آماری فونم ها — کوچک ترین بخش های گفتاری — را میسر ساخت.
مهندسان با ترکیب HMM با تکنیک های کاهش نویز، توانستند عملکرد سیستم ها را در محیط های واقعی بهبود دهند. این دوره، نقطهٔ شروع تشخیص گفتار پیوسته بود و تأثیری عمیق بر تحقیقات بعدی گذاشت.
نقش مدل های زبانی: اواخر دهه ۱۹۷۰ و دهه ۱۹۸۰
با گذشت زمان، نیاز به استفاده از معنای جمله و واژههای قبلی (context) در تشخیص گفتار احساس شد. ورود مدل های زبانی مانند مدل های trigram باعث شد که سیستم ها نه فقط صداها را بشنوند، بلکه براساس دو واژهٔ گذشته، واژهٔ بعدی را پیش بینی کنند.
در این مرحله الگوریتم هایی مانند beam search نیز وارد شدند که به سیستم امکان می دادند چند مسیر ممکن را بررسی کرده و محتمل ترین را انتخاب کنند. این پیشرفت باعث شد که سیستم های تشخیص گفتار، طبیعیتر و نزدیک تر به گفتار انسان (more human-like) عمل کنند.
شبکه عصبی و شروع یادگیری ماشین: اواخر دهه ۱۹۸۰
در اواخر دههٔ ۱۹۸۰ شبکه عصبی به حوزهٔ تشخیص گفتار راه یافت. این شبکه ها توانستند از حجم بالای داده ها الگوهای پیچیده تر را یاد بگیرند و خطاهای بین واژه های شبیه به هم را کاهش دهند.
شرکت ها در آن زمان، از این فناوری برای اتوماسیون پاسخگویی در مراکز تماس استفاده کردند؛ اما هزینهٔ محاسباتی بالا و نیاز به سخت افزار ویژه، مانعی بزرگ بود. این دوره چشم اندازی بود از آنچه در آیندهٔ تشخیص گفتار ممکن می شد.
شبکه عصبی و شروع یادگیری ماشین: اواخر دهه ۱۹۸۰
در اواخر دههٔ ۱۹۸۰ شبکه عصبی به حوزهٔ تشخیص گفتار راه یافت. این شبکه ها توانستند از حجم بالای داده ها الگوهای پیچیده تر را یاد بگیرند و خطاهای بین واژه های شبیه به هم را کاهش دهند.
شرکت ها در آن زمان، از این فناوری برای اتوماسیون پاسخگویی در مراکز تماس استفاده کردند؛ اما هزینهٔ محاسباتی بالا و نیاز به سخت افزار ویژه، مانعی بزرگ بود. این دوره چشم اندازی بود از آنچه در آیندهٔ تشخیص گفتار ممکن می شد.
یادگیری عمیق و مدل های End-to-End: دهه ۲۰۱۰
دههٔ ۲۰۱۰ آغاز دوران یادگیری عمیق در ASR بود. مدل های End-to-End که می توانستند مستقیماً صوت خام را به متن تبدیل کنند، جایگزین روش های قدیمی شدند که برای تشخیص گفتار نیاز به مراحل جداگانه مثل استخراج ویژگی های صوت، تحلیل مدل صوتی و مدل زبانی داشتند.
با داده های عظیم و سخت افزارهای قدرتمند، دقت تشخیص در زبان ها و گویش های مختلف بسیار بهبود یافت. این امر باعث شد استفادهٔ تجاری و مقیاس پذیر ASR ممکن شود.
ورود به زندگی روزمره و کسب وکارها: دهه های ۲۰۰۰ تا ۲۰۱۰
در این دوره، سیستم های تشخیص گفتار از حالت آزمایشی خارج شدند و وارد زندگی روزمره شدند. ابزارهایی مانند Google Voice Search، Siri و Alexa کاربران بسیاری یافتند.
در کسب وکارها نیز ASR کاربردهای گسترده ای یافت: از ترنسکریپشن جلسات، مراکز تماس چندزبانه، تا تحلیل احساسات و استخراج بینش از مکالمات صوتی.
این مرحله نشان دهنده بلوغ فناوری بود که استفادهٔ گسترده و اقتصادی از ASR را ممکن ساخت.
چالش های پایدار در سامانه های ASR
با وجود پیشرفت های بزرگ، هنوز موانعی وجود دارد که بر استفادهٔ بهینهٔ ASR تأثیر می گذارند:
– نویز محیطی: حضور صداهای پس زمینه، طنین اتاق، چند گوینده بودن و … دقت را کاهش می دهند.
– تنوع زبان و لهجه: مدل های آموزش دیده معمولاً روی انگلیسی آمریکایی متمرکز هستند و با لهجه ها یا زبان های کم منبع عملکرد ضعیف تری دارند.
– منابع محاسباتی و هزینه ها: آموزش مدل های پیشرفته مصرف انرژی بالایی دارد و برای کسب وکارهای کوچک دشوار است.
مقایسه نسل ها و چشم انداز آینده
– دههٔ ۱۹۵۰ تا ۱۹۶۰: شروع تلاشها برای تشخیص اعداد و کلمات محدود با سیستمهای مبتنی بر قواعد و منطق ساده (Rule-based).
مثال: سیستم Audrey از Bell Labs فقط ۱۰ رقم را تشخیص میداد.
– دههٔ ۱۹۷۰ تا اواخر ۱۹۸۰: ظهور مدلهای پنهان مارکوف (HMM) و مدلهای زبانی آماری مثل تریگرام (Trigram).
این دوران نقطهٔ عطفی بود چون برای اولین بار سیستمها توانستند جملات طبیعی را با در نظر گرفتن احتمال کلمات پیشبینی کنند.
– اواخر دههٔ ۱۹۸۰ تا دههٔ ۱۹۹۰: ورود شبکههای عصبی اولیه (Neural Networks) که هرچند محدود بودند، اما مسیر را برای درک الگوهای پیچیدهٔ صوتی باز کردند.
در این دوره استفاده از دادههای بزرگتر و سختافزارهای قدرتمندتر هم شروع شد.
– دههٔ ۲۰۱۰ تا امروز (۲۰۲۰–۲۰۲۵): دوران یادگیری عمیق (Deep Learning) و مدلهای End-to-End مثل DeepSpeech و Transformer-based ASR.
این نسل سیستمهایی را بهوجود آورد که میتوانند مستقیماً از موج صوتی تا متن خروجی را بدون واسطه تحلیل کنند، با دقتی نزدیک به انسان.
* در آینده، فناوری هایی مانند معماری های Transformer، پشتیبانی گسترده از لهجه ها و زبان های گوناگون، تعامل صوتی-متنی هم زمان و اجرای محاسبات هوش مصنوعی روی خود دستگاه (Edge Computing) نقش پررنگ تری خواهند داشت.
توصیه های کاربردی برای کسب و کار ها
برای شرکت ها و سازمان هایی که می خواهند از ASR بهره ببرند، نکات زیر می تواند راهگشا باشد:
– محیط صوتی خود را تحلیل کنید: اگر نویز زیاد است، از مدل های تخصصی یا میکروفون های بهبود یافته استفاده شود.
– احتیاج های زبانی و لهجه ای کاربران را بررسی کنید و راهکاری انتخاب کنید که از تنوع پشتیبانی می کند.
– مقیاس استفاده را از کم شروع کرده و در صورت موفقیت به راهکارهای داخلی یا ترکیبی ارتقا دهید.
– هزینهٔ محاسباتی و زیرساخت را در نظر بگیرید؛ مدل های کم هزینه تر اما بهینه شده می توانند انتخاب مناسبی باشند.
– امنیت داده و حریم خصوصی را فراموش نکنید، به ویژه در صنایع حساس مانند سلامت یا مالی.
چرا این مسیر برای ما اهمیت دارد؟
درک تاریخچهٔ ASR به ما کمک می کند بفهمیم چرا فناوری تا این حد پیشرفته شده و چه محدودیت هایی هنوز باقی است. این شناخت باعث می شود انتخاب بهتری برای راهکار آینده داشته باشیم و با آگاهی، از مزایای این فناوری بهره ببریم.
چه در محیط های صنعتی، چه در زندگی روزمره، ASR امروز تبدیل به ابزاری کلیدی شده است و فردا نقش گسترده تری خواهد یافت.


